· Test Automation · 11 min read
The 5 Pillars of a Cypress Automated Test Framework
Cypress series Part 2. Creating a robust testing framework using Cypress involves several foundational principles ensuring maintainability, clarity, and effectiveness in web application testing. Below are the five pillars that should guide the implementation of a Cypress-integrated test framework.

Overview
This comprehensive guide outlines five fundamental pillars for building a robust Cypress automated testing framework. The pillars consist of Test Code Complexity, which emphasises keeping test scripts simple while abstracting complex logic into the framework; Test Scope, which focuses on targeting actual end-to-end user flows while avoiding external service testing; Realistic User Test Data, which stresses the importance of dynamic and evolving test data management; Selecting Elements, which advocates for Flat Page Object Models (FPOMs) for efficient element selection; and Valid Test Environments, which details a three-stage testing approach across local (Dockerized/VM), staging, and QA production environments.
These pillars form our template for creating maintainable, efficient, and effective automated testing frameworks that can scale while providing actual software quality feedback to the development team.
1. Code Complexity
Minimising Complexity in Test Scripts
This first pillar emphasises that test scripts should maintain the lowest complexity possible; the scripts need to be readable and accessible to amend when the application under test changes. In contrast, the code composing the integrated test framework holds all the complex logic required for the test scripts. This means abstracting complex operations and logic into commands and crafting code to write the integrated framework. Doing so makes test scripts more straightforward to read and understand, enabling team members of varying technical backgrounds to engage with them effectively. This aligns with best practices in software development, where simplicity and clarity are paramount for long-term maintenance and collaboration[1][2].
A typical example of this concept would be the login flow, the selection of the test user for the test script, or the assertions to be checked in a test. For example, here is how we would handle a verification code to perform in many test scripts. We should implement a custom command with all the complex assertions and checks for the same test intention. The Cypress command can have as many checks as necessary to achieve the intent of the assertion.
// Context: An application which displays a list of resources.
// ... test steps
// Verification
cy.assertExistsResource(name);
// The command in the commands.js file hides all the complexity.
// 'mainPage' is a FPOM.(more on this later)
Cypress.Commands.add('assertExistsResource', (resourceName) => {
mainPage.getItemsList().within(() => {
cy.getDataTestElm(`'${resourceName}'`)
.should('exist');
});
});
Encapsulation of Test Logic
It is essential to keep any test logic not directly related to the test intent separate from the test scripts, i.e. the logic for selecting elements, navigating, and requesting extra test data. This separation provides better test script readability and ensures the test intention is captured within the test scripts. The more complex operations are moved within commands or better within the integrated framework, designed for proper test coverage, enhancing maintainability and reducing complexity.
For example, let’s consider the test script that needs to navigate some tabs or folders on the screen.
// The test script could just read like
cy.openFolder('QAContent');
// The 'mainPage' is a FPOM. The cypress command is like:
Cypress.Commands.add('openFolder', (folderName) => {
mainPage.getFoldersList().within(() => {
cy.findByText(folderName).click();
});
});
Implementing a BDD Layer
Incorporating a Behavior-Driven Development (BDD) layer can benefit larger organisations where there is actual demand to communicate the test intentions, usually with people beyond the development team. BDD allows for writing tests in natural language, making them more accessible to stakeholders who may not be familiar with programming. This layer can help clarify the intent behind tests, ensuring that the test coverage aligns with business requirements and user expectations[1]. However, adding a BDD layer just to use BDD as “a good practice” is not recommended. For a single development team, having test scripts written in simple and readable code is much more efficient in the mid-and long-term. One of the best BDD frameworks we have worked with is the Serenity BDD, specifically when leveraging the screenplay pattern. This is a pattern worth investing in when BDD is required.
Descriptive Naming Conventions
Tests should have clear titles that reflect their test intentions. This practice not only aids in understanding but also helps organise tests into groups based on higher-order intentions rather than mere features. For instance, different tests might focus on a user’s behaviour under various scenarios (e.g., expected good vs. malicious user flows, providing deeper insights into application performance under varied conditions).
For example, consider the following tests:
// Bad test name
it('Create user')...
// A more descriptive name could be
it('A new user should be created with default values')...
2. Test Scope
Targeted End-to-End Testing
The second pillar stresses the importance of narrowing the focus of tests to actual end-to-end (E2E) user flows within the application. It is crucial to avoid testing external services that are not part of the application under test. For example, verifying that a Gmail service account receives emails may be tempting, but this is outside the scope of your application’s functionality. Instead, confirm your application can send emails correctly by stubbing or mocking the SMTP server during tests[3].
Testing Framework Integrity
A vital aspect of maintaining a testing framework is ensuring all supporting code for test scripts undergo unit and integration testing. This means avoiding implementing generic utility functions. Instead, we should implement well-named actions encapsulated in classes or functions that should be thoroughly tested[4]. This approach enhances reusability, clarity and maintainability within the framework’s codebase.
For example, some parsing utils are expected to be needed to extract numbers from href URLs.
// The test script could use a custom parsing function like this:
let elemId = urlParser.getNumberFromUrl(anchorElement.attr("href"));
cy.log(elemId);
// The function could be implemented in a 'urlParser' javascript module.
// cypress/support/fwk/urlParser.mjs
class UrlParser {
getNumberFromUrl(pathName) {
return pathName.substr(pathName.lastIndexOf('/') + 1).replace(/\D/g, '');
}
...
// And the Unit test should be.
it('Should extract the last number id of a URL path name.', () => {
let id = urlParser.getNumberFromUrl('/test/collection/edit/3097');
assert(id == '3097');
let id2 = urlParser.getNumberFromUrl('/test/collection/edit/1/3097');
assert(id2 == '3097');
//... more assertions as needed for the API verification
});
3. Realistic User Test Data
Dynamic Test Data Management
The third pillar highlights the necessity of generating realistic user test data that evolves alongside business requirements. Static test data quickly becomes outdated, leading to irrelevant tests that do not accurately reflect user interactions or system states. To keep test data relevant, it should be continuously updated to reflect changes in business logic and user behaviour[5].
Automation of Test Data Generation
Automating test data generation, not just test scripts, can significantly enhance efficiency. Techniques such as Faker libraries or AI-driven solutions can help create dynamic datasets that mirror real-world scenarios[6]. Additionally, custom tooling or scripts can facilitate recording previous tests or user actions, ensuring test data remains aligned with actual user interactions.[7]
A distinctive situation is when we need a specific user object with some sample data:
// The test script could read like:
const memberAccount = members.generateNewAccount(TEST_PREFIX);
// Then the integated framework leverages a FAKER library
// within a well tested function like the following:
// 'customFakes' can be a custom wrapper around the facker library or
// an advanced tool to fetch and populate fixtures.
generateAssociatedRegistrationData(PREFIX) {
return {
person: { firstName: PREFIX + faker.name.firstName(),
lastName: faker.name.lastName(),
nationalId: customFakes.nationalId(),
dateOfBirth: customFakes.pastDate(20),
gender: "FEMALE",
addresses: [
{ street: faker.address.streetName(),
postalCode: "90210",
city: { name: "BEVERLY HILLS", cityId: 12345, },
state: "CALIFORNIA", email: faker.internet.email(),
officialEmail: faker.internet.email(),
mobile: faker.phone.number('(555) ### ####'),
mainPhone: faker.phone.number('(310) ### ####') }] },
status: "ACTIVE",
registrationDate: customFakes.pastDate(20),
membershipStatus: { membershipStatusId: 1 }}}
4. Selecting Elements
Utilising Flat Page Object Models (FPOMs)
The fourth pillar advocates for a robust element selection system. We like to use the Flat Page Object Models (FPOMs) system. These objects only contain the most straightforward possible logic to find the elements required for the test scripts; no other logic is implemented. Keeping the FPOMs flat is critical to preserving the framework’s low complexity and long-term maintainability. A Flat POM structure simplifies element selection by ensuring only one method for locating any given element within tests. These objects are not coupled, aggregated or used as ordinary code objects; the FPOMs are like simple collections decoupled from everything else. This encapsulation minimises redundancy and potential errors associated with element selection across various tests.[8]
An example of a FPOM could be like this:
// Example of a FPOM for a specific form.
export class AssociateForm {
getEditButton() { return cy.findByText('Edit') }
getSummarySection() { return cy.get('.memberContactAddressSummary'); }
getNavigationTabs() { return cy.getDataTestElm('nav-tabs'); }
getReceiptsTab() { return cy.get('#receipts'); }
getNewReceiptDropdown() {
return cy.get('.dropdown-menu.dropdown-menu-right.dropDownNewOptions.show'); }
getCategoriesTab() { return cy.get('#categories'); }
getActivitiesTab() { return cy.get('#activities'); }
}
// The test script only need to import and use this FOPM like this:
import {FormAssociate} from "../../support/pom/formAssociate";
...
const formAssociate = new FormAssociate();
...
it('Create a valid new activity filling up the Associate form.', ()=>{
...
formAssociate.getNavigationTabs().findByText('Categories').click();
);
5. Valid Test Environments
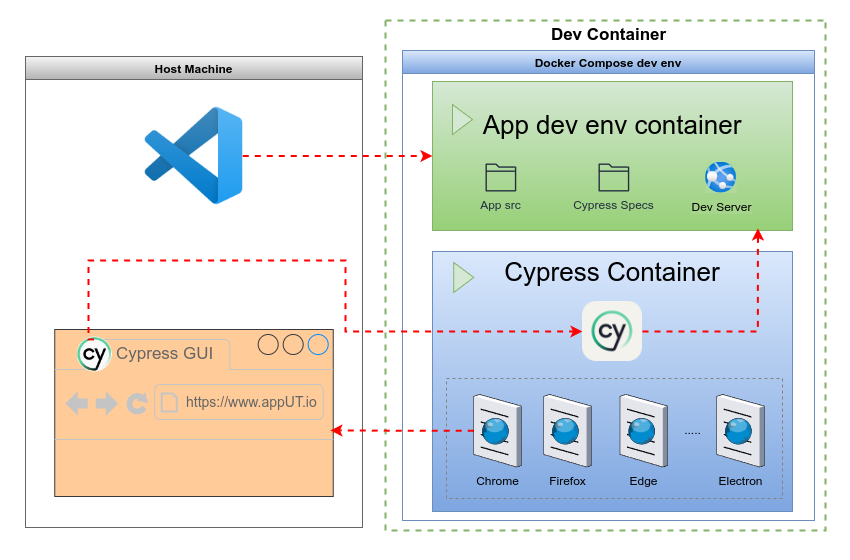
The fifth pillar, establishing a robust testing strategy across multiple environments, is crucial for ensuring the quality and credibility of the test results. We like to call this approach the “Three Stages of Test Development,” which involves progressing through local, staging, and production QA environments. Each stage serves a specific purpose in the testing lifecycle, allowing for thorough validation of the test scripts and test performance under different conditions.
Dockerized/VM Local Environment
The first stage in the test development process involves implementing and running tests in a virtualised local environment, typically using Docker containers or virtual machines (VMs). This approach offers several advantages:
Isolation and Consistency: Docker containers provide a consistent and isolated environment for running tests, ensuring that all developers work with the same configuration regardless of their local setup. This consistency minimises the “it works on my machine” problem and helps identify issues early in development.
Rapid Iteration: Local, high-quality development environments allow developers to iterate on tests quickly, making adjustments and improvements without affecting shared resources. This agility is crucial for the initial stages of test development, where frequent changes are expected. Suppose the local dev environment does not facilitate writing and running tests while implementing new code. In that case, all the rest of the test automation efforts will not add much value.
Resource Efficiency: Containerisation efficiently uses system resources, enabling developers to run multiple test environments simultaneously without significant overhead[3].
We have this other blog post with full details on setting up an excellent local development environment with a proper Cypress test environment. https://testautomationagency.com/cdc
Staging Environment
Once the tests have been developed and validated locally, they are promoted to a QA staging environment. This environment closely mimics the production setup. However, the test reports are not directly shared with the development team. The staging phase is crucial for several reasons:
Test stability: The primary objective of running the test in this environment is to control and minimise the false positive and false negative test results. The QA or dev teams review these test results not only for the application’s correctness but also for the test’s reliability. So, to say it clearly, we verify that the tests are testing the right intentions and are not flaky.
Integration Testing: Staging allows for comprehensive integration testing, where multiple application components can be tested in a production-like environment. The team has more tools and test environments to explore and do proper Proof of Concepts about new integration testing strategies. For example, the tests can be targeted to verify non-production development environments and/or specific builds.
Performance Validation: It provides an opportunity to assess the performance of test executions, not the application’s performance under test, but the test executions in more realistic conditions than the local dev environment.
CI/CD Integration: Tests in the staging environment are typically integrated into continuous integration and continuous deployment (CI/CD) pipelines, allowing for automated testing as part of the deployment process.
Once a QA Engineer validates the test reliability, the tests can be promoted to the QA production environment.
QA Production Environment
The final stage involves running tests in a quality production environment. This step is the actual testing phase of executing the test scripts. The test reports will be shared with the development team and all the QA stakeholders. It’s essential to note that only stable and well-vetted tests should be promoted to this level to avoid potential disruptions to the software development process and the live services. The key concept is to minimise false interruptions for the development team and report as much valuable testing information as possible.
Smoke Tests: In production, it’s typical to run a subset of critical tests, often called smoke tests, to verify core functionality without extensive testing that could impact performance. These tests are usually executed after major or risky deployments and target the application’s pre- and production environments.
Monitoring and Observability: Production test runs should be closely monitored, with results feeding into observability tools to identify and address any issues that arise quickly.
By adhering to these five pillars—test Code Complexity, Test Scope, Realistic Test Data Management, effective element identification, and maintaining Valid Test Environments—teams can build a more robust Cypress integrated test framework that enhances productivity and software quality over time.
References:
- [1] https://www.cypress.io/blog/crafting-a-robust-testing-strategy-a-comprehensive-guide-to-scale-your-testing-efforts
- [2] https://bugbug.io/blog/testing-frameworks/cypress-best-practices/
- [3] https://www.javierbrea.com/blog/cypress-mock-server/
- [4] https://stackoverflow.com/questions/70072966/how-do-i-write-unit-tests-in-cypress-is-that-even-possible
- [5] https://learn.cypress.io/advanced-cypress-concepts/using-data-to-build-dynamic-tests
- [6] https://fakerjs.dev/
- [7] https://www.classace.io/answers/explain-the-importance-of-collecting-and-recording-required-test-data
- [8] https://www.selenium.dev/documentation/test_practices/encouraged/page_object_models/
For further details, questions and corrections: Lets connect